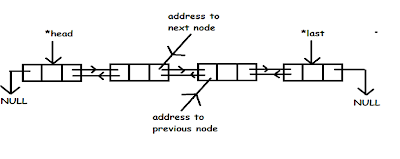
Angular 2 Dependency Injection
What is dependency injection (DI) Dependency injection is a feature of a dynamic language that we quite often use in JAVA web applications and .NET applications. This feature enables efficient re-use of code and instances thus making the programs more memory efficient and light weight, still at the cost of a few additional lines of code (CPU cycles). This could also in turn provide the programmer with the benefit of design patterns such as Singleton and Factory patterns without having to code them from scratch (We will discover how as we proceed). To conclude what is DI, it's a mean by which we inject an instance of an object (called services in Angular 2) to another Object (mostly to a component) in order to have clean code and reusable code. Advantages of DI Improved changeability Since the object creation is taken away from the components that uses the object, we no longer worry about the object constructor. Which is great if we're to work in large teams, which mi...